RecA: Reconstruction Alignment Improves Unified Multimodal Models
Unlocking the Massive Zero-shot Potential in Unified Multimodal Models through Self-supervised Learning
UC Berkeley
UC Berkeley
University of Washington
UC Berkeley
UC Berkeley
UC Berkeley
University of Washington
UC Berkeley
Click on images to see their generation prompts below











Drag the slider to compare original images with their edited versions












Unified multimodal models (UMMs) unify visual understanding and generation within a single architecture. However, conventional training relies on image–text pairs (or sequences) whose captions are typically sparse and miss fine-grained visual details—even when they use hundreds of words to describe a simple image.
We introduce Reconstruction Alignment (RecA), a resource-efficient post-training method that leverages visual understanding encoder embeddings as dense "text prompts," providing rich supervision without captions. Concretely, RecA conditions a UMM on its own visual understanding embeddings and optimizes it to reconstruct the input image with a self-supervised reconstruction loss, thereby realigning understanding and generation. Importantly, RecA does not require any image-to-text paired data, relying purely on image reconstruction for training.
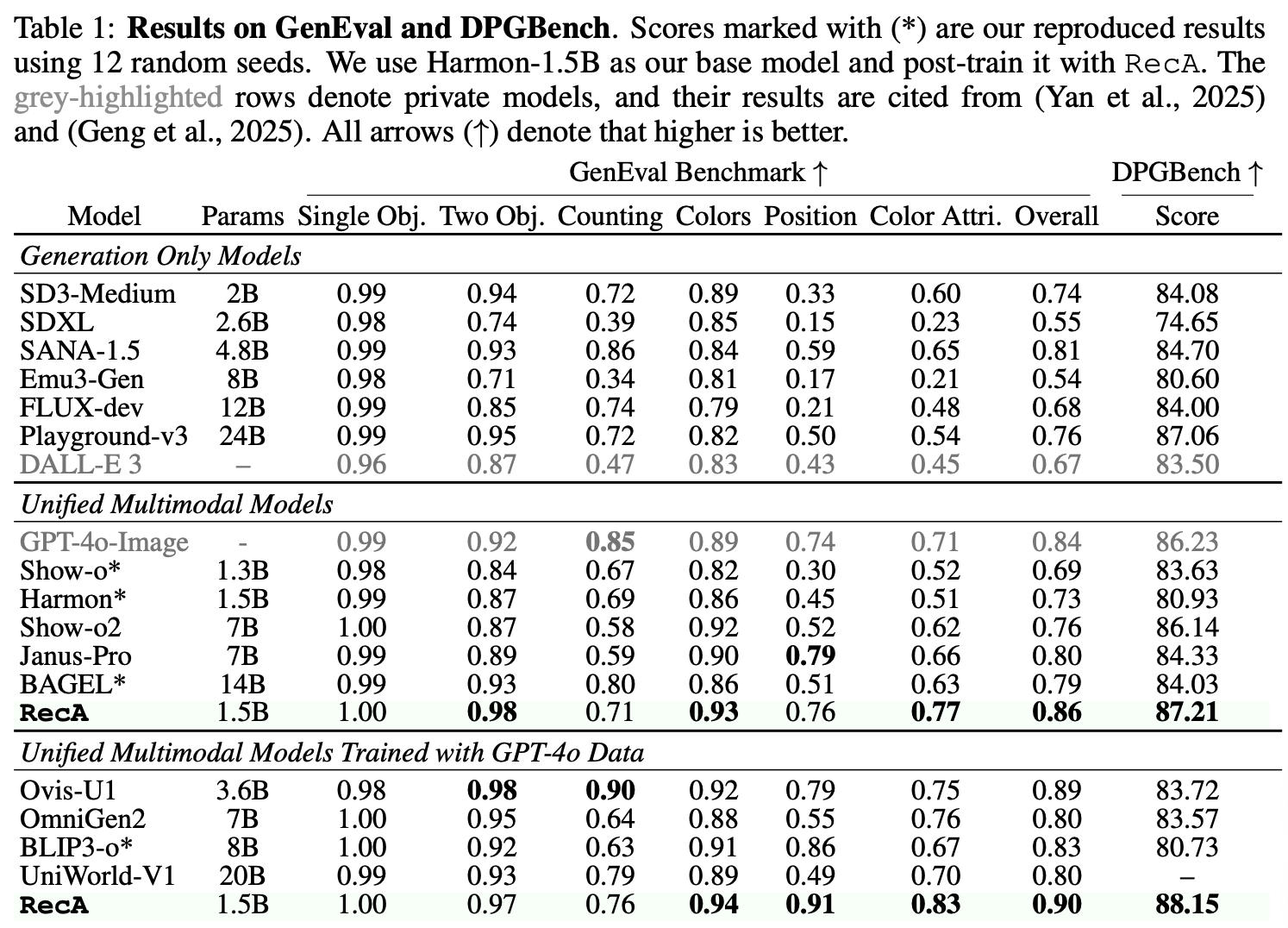
Despite its simplicity, RecA is broadly applicable: across autoregressive, masked-autoregressive, and diffusion-based UMMs, it consistently improves generation and editing fidelity. With only 27 GPU-hours, post-training with RecA substantially improves image generation performance on GenEval (0.73→0.90) and DPGBench (80.93→88.15), while also boosting editing benchmarks (ImgEdit 3.38→3.75, GEdit 6.94→7.25).
Notably, RecA surpasses much larger open-source models and applies broadly across diverse UMM architectures, establishing it as an efficient and general post-training alignment strategy for UMMs.
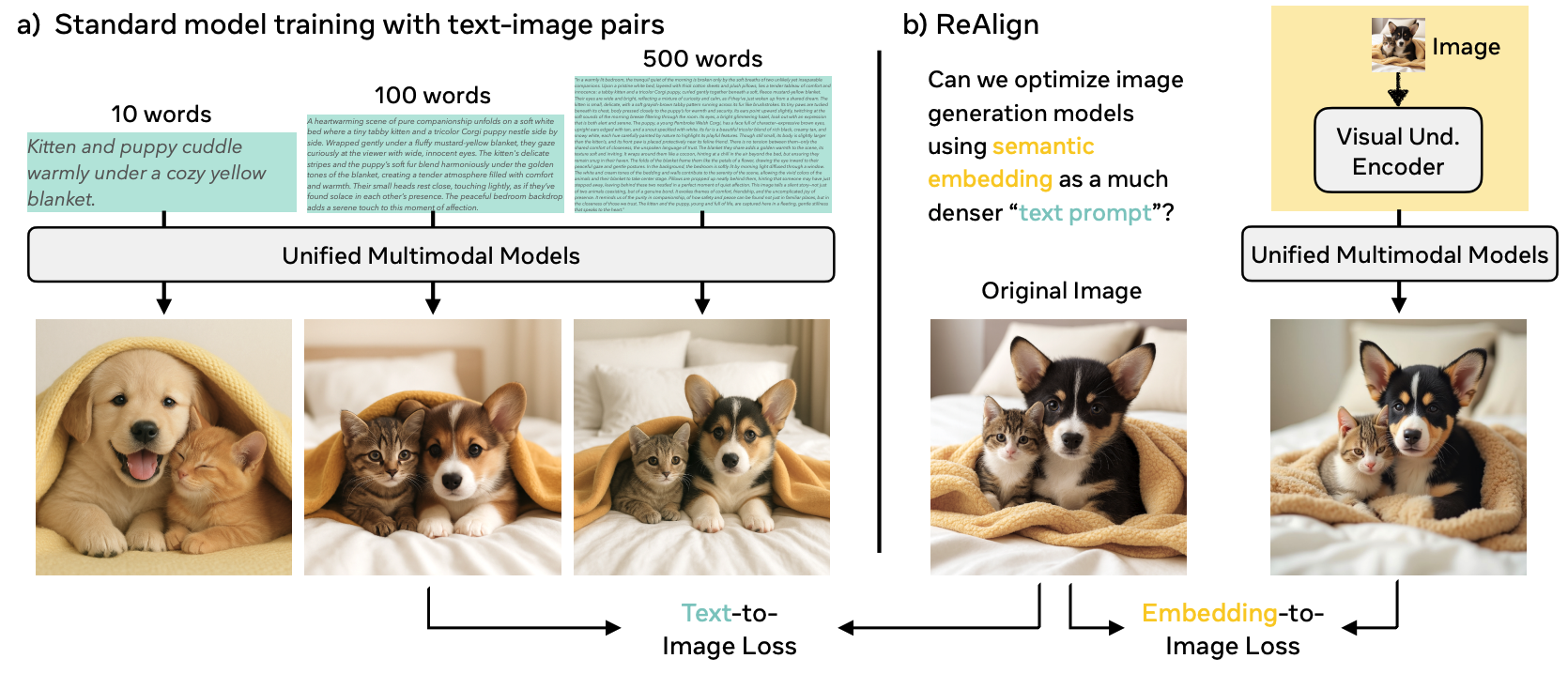
Dense supervision from visual embeddings. (a) Typical image generation models are trained on image-caption pairs where text provides only sparse supervision. (b) By contrast, embeddings from visual understanding encoders preserve richer and more faithful semantics.
Conventional training of Unified Multimodal Models (UMMs) relies on image-text pairs, where captions provide supervision. However, even captions spanning hundreds of words omit critical visual details:
"An image is worth far more than a hundred words" — even lengthy captions miss key aspects, leading to biased correlations like broccoli → green.
Instead of relying on sparse text captions, we leverage visual understanding encoder embeddings that map pixels into a language-aligned semantic space:
Can we improve generation capabilities by training UMMs with semantic embeddings as maximally informative "visual prompts"?
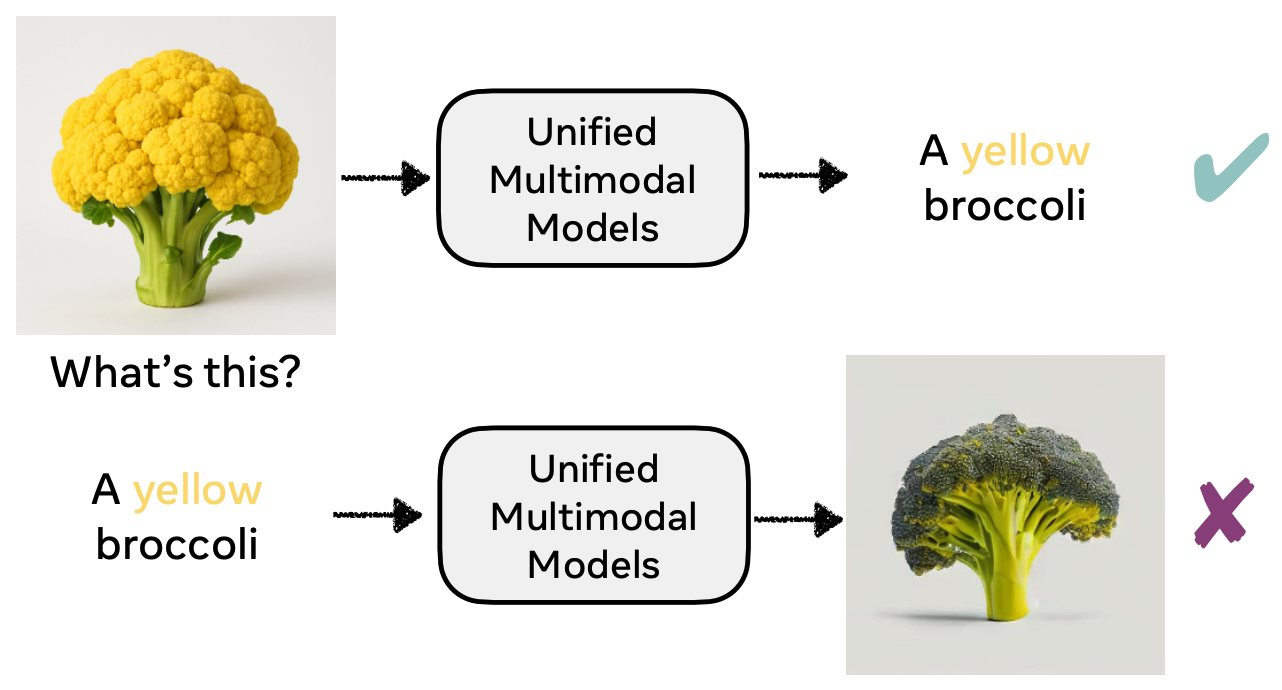
Example: UMMs can often correctly recognize an uncommon concept (yellow broccoli) but fail to generate it, revealing misalignment between understanding and generation.
✅ Can recognize "yellow broccoli"
❌ Fails to generate "yellow broccoli"
The Gap: UMMs often understand concepts they cannot generate, revealing fundamental misalignment between understanding and generation pathways.
RecA requires NO image-to-text paired data for training. Instead, we use pure image-to-image reconstruction with understanding visual embeddings as supervision. This eliminates the dependency on captioned datasets and the limitations of sparse textual descriptions.
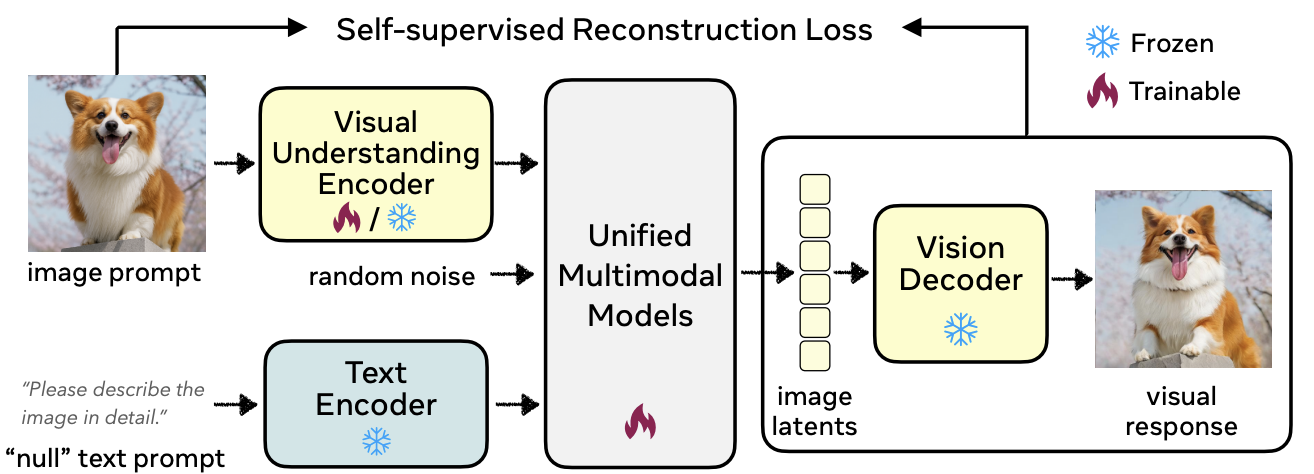
RecA Pipeline: At inference time, RecA requires no additional inputs beyond the text prompt, operating exactly like a standard UMM.
Overview of the semantic reconstruction realignment (RecA) pipeline. A visual understanding encoder (e.g., CLIP or DINO) extracts semantic features from the input image, which are fused with template text embeddings and passed to a Unified Multimodal Model (UMM) to regenerate the image.
RecA implements a self-supervised training paradigm where the UMM is optimized with a reconstruction loss (diffusion or cross-entropy) between the original and reconstructed images. This approach provides dense supervision that preserves almost all fine-grained details that captions omit.
We freeze the visual understanding encoder in most cases, except when the UMM employs the same encoder for both tasks (e.g., Harmon with MAE).
For UMMs that share parameters between understanding and generation, we preserve image-to-text capability with LLaVA data; otherwise, we freeze understanding entirely.
We do not use text-to-image data. RecA relies purely on image reconstruction with understanding visual embeddings as supervision.
Input images are resized to minimum resolution accepted by the visual encoder (e.g., 224×224 for SigLIP).
Pure image reconstruction without relying on text captions or paired data.
Dense visual features are extracted from understanding encoders (CLIP, SigLIP, etc.) as "visual prompts", not from generation encoders (VAE).
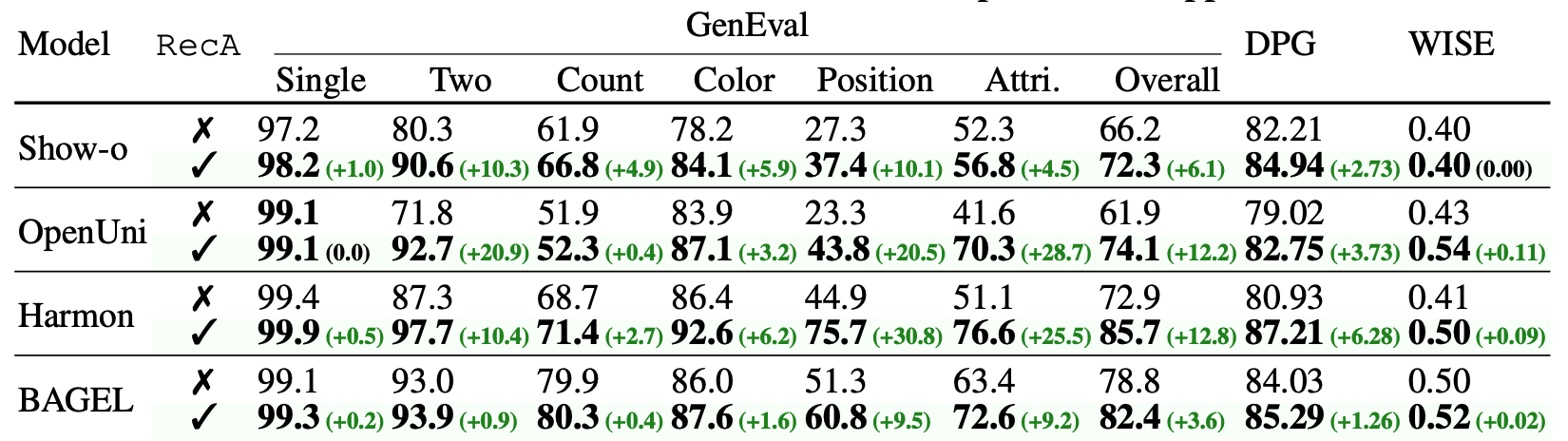
After only a few training steps, all models post large zero-shot gains in generation capability with no loss in vision-understanding accuracy. Our fine-tuned Harmon model, even with just 1.5B parameters, achieves a high score of 0.86 on GenEval and 87.21 on DPGBench, significantly outperforming the previous state-of-the-art models without any GPT-4o-Image distillation data or reinforcement learning.
The most effective approach is a two-stage strategy: first applying SFT followed by reconstruction tuning, which achieves 0.90 on GenEval and 88.15 on DPGBench.
Across Different Architectures and Tasks
RecA achieves consistent performance gains across different UMM frameworks, showcasing its generalizability. We apply RecA to various unified multimodal models including Show-o (AR), Harmon (AR+MAR), OpenUni (AR+Diffusion), and BAGEL (AR+Diffusion).
All models demonstrate significant improvements through RecA: the most notable improvement is achieved by Harmon-1.5B with 85.7 GenEval score (+12.8). Our method exhibits the most significant gains in Position and Color Attribution tasks, while maintaining correct subjects, bindings, and positions across cases with multiple objects, complex attributions, and explicit spatial layouts.
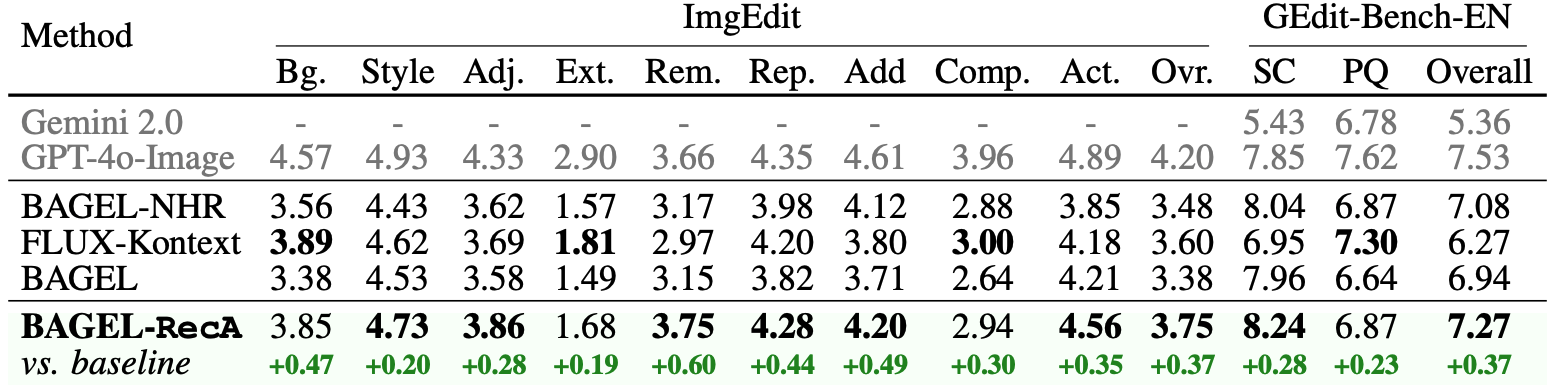
We surprisingly discover that, for models with image editing capabilities, our method also significantly improves their editing performance. RecA demonstrates consistent improvements across all editing categories, increasing the ImgEdit scores from 3.38 to 3.75 and GEdit from 6.94 to 7.25, using only 1,000 training steps and 8,000 unlabeled images.
Our method unlocks the model's inherent editing potential without expensive annotation across various tasks like addition, replacement, stylization and color modification.
Thank you for visiting our research page!